Last night we let our users down.
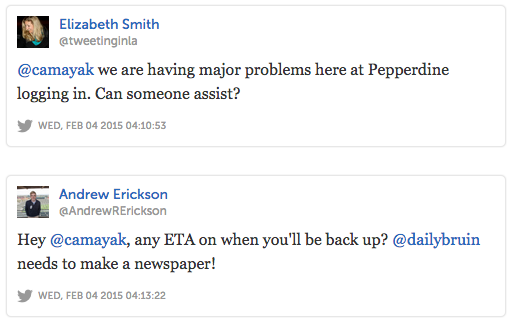
At around 10pm Central Time, the Editor-in-Chief of the Kansas State Collegian emailed our support address to tell us that his staff had been unable to log into Camayak for ten minutes. Usually he would have expected a reply from us within the next fifteen, telling him what was up and what we were doing to fix it.
Minutes later, the student media adviser at Pepperdine University and Editor in Chief of UCLA’s Daily Bruin both asked for help, too: Camayak wasn’t responding normally and had now been periodically inaccessible for at least twenty minutes.
As anyone who uses Camayak knows, the whole point is to have real-time access to your newsroom, 24/7, no matter where you are. We work to maintain that standard because it’s an essential part of our service and also because people rely on us to produce their work on deadline.
But last night, after thirty minutes of intermittent service, we still hadn’t responded to the people letting us know that we had a job to do.

Then, minutes-that-felt-like-hours later and still without any support response from us, Camayak seemed to return to normal and newsrooms from around the country reported that their staff were able to keep working.
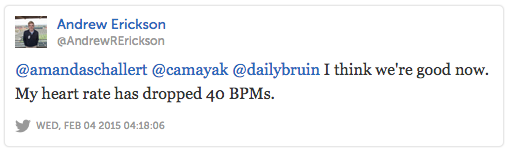
But it didn’t last. Less than half an hour later, we received more alerts from other newsrooms of service interruptions that in some cases hadn’t let up since they’d first been reported.
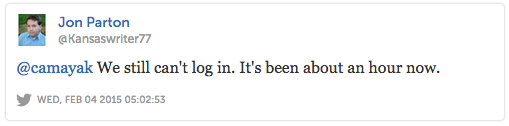
By this point it was abundantly clear that we’d let our users down on two counts. They’d been forced to deal with unplanned downtime and even more confusingly, were doing so without any guidance from us.
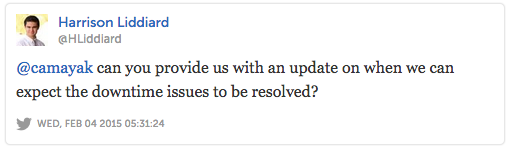
Finally, at 11.45pm CST – a full two hours after the Kansas State Collegian had first reported difficulties accessing Camayak – we recovered full service.
This morning, over an hour and half later, we sent our first responses to the people who’d reached out to us for help.
Why we messed up
First off, we’re profoundly sorry for letting our users down on two fronts last night. People use Camayak because it’s a more efficient way to work and we’ve always prided ourselves on our response times to any urgent difficulties our users are having.
So what went wrong?
Downtime
Last night we experienced an outage, which we’re currently investigating. We’ll be updating our blog with our root cause analysis, later.
Usually we’re in a position to react to such outages by monitoring our systems and adapt on-the-fly. Unusually, we didn’t respond like that last night. This is because we had a gap in our engineering and support coverage.
Lack of support
We’re used to ‘after hours’ questions from newsrooms, because that’s often when newsrooms get busy. We also work with newsrooms that are based in Pacific and other ‘later’ timezones. So the timing of last night’s issues was not outside of our predictable scope of activity.
We’re a distributed company – which comes with timezone/support benefits – and decided three years ago that having a co-founder on the same timezone as many of our users was a sensible idea (we also have coverage for Central, Eastern and GMT/BST timezones). I’ve been living in Los Angeles ever since and am usually the first to respond to support questions from the Pacific timezones. We aim to get back to urgent requests within ten minutes.
Last night however, I was not on the West Coast and our Central hub was off duty as our downtime began. As you’ll see from the time-stamps in this post, I’m currently in London, along with our GMT/BST hub that only came on duty at 6.30am local time (12.30am CST and 10.30pm PST).
While these were highly unusual circumstances for our service and team, they shouldn’t have affected our service levels and we deeply regret that they did.
What we’re going to do about it
We’re going to publish the results of our root cause analysis for the outage Camayak experienced. Update: our analysis and remediations are listed here.
Despite being spread across multiple timezones, we’re also taking steps to make sure our engineers and support team can be alerted to critical needs, even when they’re not on-call. The situation we ran into last night has never happened before but is a timely reminder for us to make sure we have a plan in place for urgent events that might occur when we’re all asleep or off duty.
We’re hugely grateful for how responsive and patient our users are and won’t forget this as an example of how we can keep improving. We messed up and are determined not to let it happen again.
If you’d like to follow-up with me, please reach out to roman@camayak.com.