
Back in 2014 TownNews, the CMS provider that currently serves over 1,600 media organizations announced an integration with Camayak to help …
Service Updates
Introducing: Shopify blogs integration
We've been hard at work expanding Camayak to additional platforms, and today we are introducing a Shopify blogs integration. This …
We’re updating our Privacy Terms

You’ve probably heard that from May 25th, people living in Europe will have an easier time understanding how their personal data is being …
Camayak scheduled downtime tomorrow and May 2nd
Tomorrow and on May 2nd we’re going to be performing system maintenance, which we expect to take under one hour. You won’t be …
Spectre & Meltdown CPU patches
Over the coming week Camayak will need to schedule short (up to one/two hours, but usually taking approximately 30 minutes) downtime windows …
Camayak scheduled downtime on Monday and Wednesday this week

Tomorrow and Wednesday October 21st 2015, we're going to be performing system updates. You won't be able to access Camayak during these …
Root Cause Analysis for Camayak Outage of February 3rd/4th
Overview Camayak customers experienced three service outages though the evening hours of February 3rd (US Time Zones)/Early Morning …
How We Messed Up
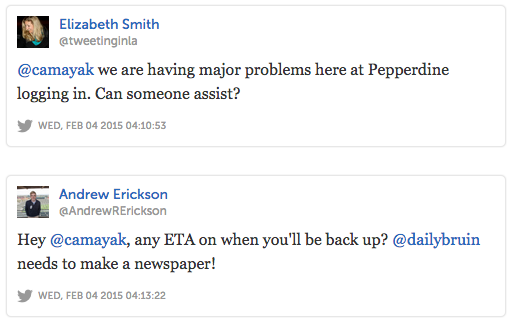
Last night we let our users down. At around 10pm Central Time, the Editor-in-Chief of the Kansas State Collegian emailed our support address …
We Messed Up
This evening, we messed up. Over the last four hours you may have been affected by several periods of Camayak downtime that have prevented …